Data Mesh - Not Such a New Concept After All?
Not such a new concept after all?
I don’t think that I have to tell much about the recent developments on Data Mesh (see this and that), the world doesn’t need another “Data Mesh introduction” article just to tell these things again.
But when we dig deeper into that topic and look on the Data Product there might be some similarities ringing a bell. We’ll come to this later.
But how is a Data Product defined (by Zhamak)?
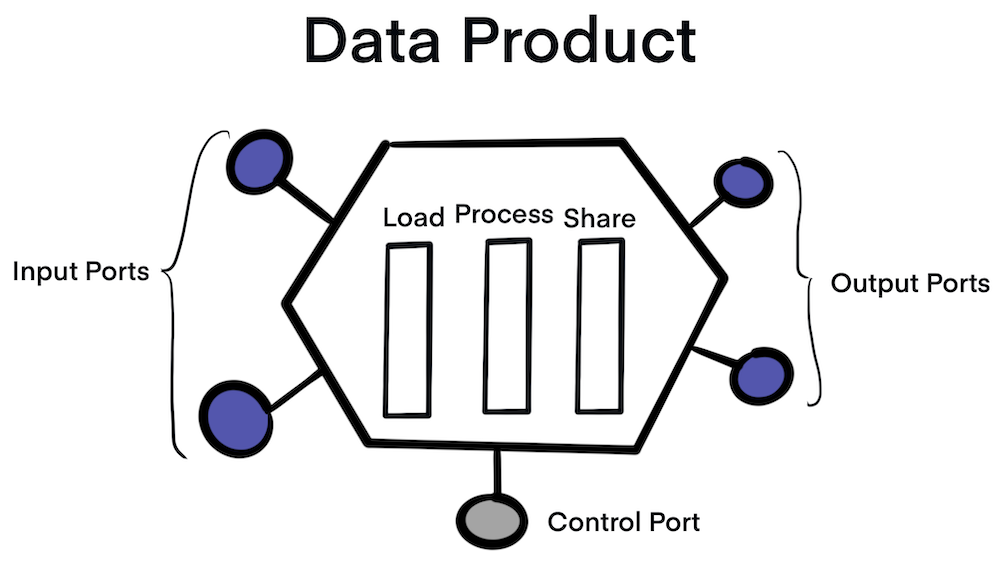
Data product is the node on the mesh that encapsulates three structural components required for its function, providing access to domain’s analytical data as a product.
Code: it includes (a) code for data pipelines responsible for consuming, transforming and serving upstream data - data received from domain’s operational system or an upstream data product; (b) code for APIs that provide access to data, semantic and syntax schema, observability metrics and other metadata; (c) code for enforcing traits such as access control policies, compliance, provenance, etc.
Data and Metadata: well that’s what we are all here for, the underlying analytical and historical data in a polyglot form. Depending on the nature of the domain data and its consumption models, data can be served as events, batch files, relational tables, graphs, etc., while maintaining the same semantic. For data to be usable there is an associated set of metadata including data computational documentation, semantic and syntax declaration, quality metrics, etc; metadata that is intrinsic to the data e.g. its semantic definition, and metadeta that communicates the traits used by computational governance to implement the expected behavior e.g. access control policies.
Infrastructure: The infrastructure component enables building, deploying and running the data product’s code, as well as storage and access to big data and metadata.
Additionally, we have the three types of ports.
- Input Ports
- Output Ports
- Control Ports
This looks really interesting and quite new, if you remember how the usual work in the data & analytics domain was done previously. But times have changed, principles like Infrastructure as Code, serverles, DevOps & DataOps, SRE etc. have changed the game towards more code focussed and software engineering thinking.
This morning I stumpled across a nice article on cloud serverless lock-in. One approach here is the hexagonal architecture, in which Ports and Adapters are present.
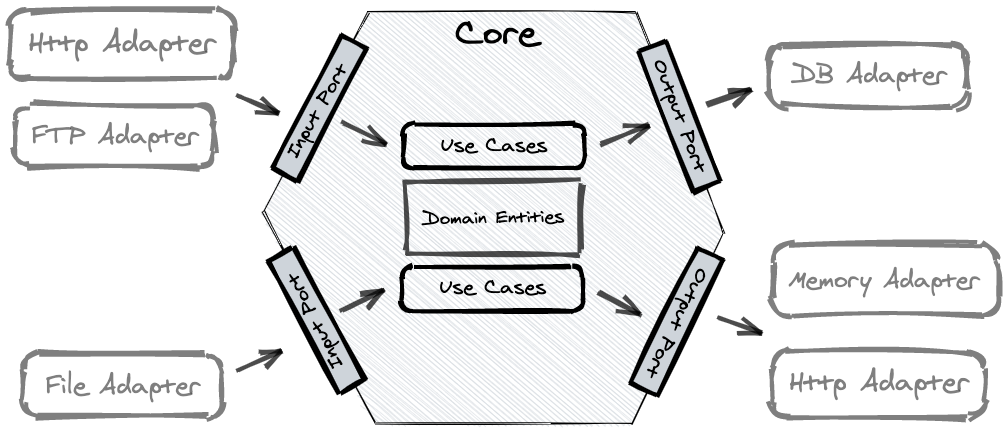
The goal of the hexagonal architecture is to encapsulate the logic within the core from the outer world. With this one, you can leverage some benefits:
- easier testing in isolation
- development can be done independently from external services
- ports and adapters are replaceable / extandable
Now let’s try to map it to the Data Product from Data Mesh. The Data Product is connected via the Input Port(s) to the data sources, this can be a database (e.g. via jdbc), a Message Queue / Message Broker like Kafka, Web endpoints etc.
Then within the Data Product, the “standard” procedures of Load, Process and Provide are happening. They load the data from the source via the input port (or receive events via subscription e.g. to a Kafka topic), do some data transformation steps ( = process) and provide the outcome via the Output Port(s). This can be again a database or a S3 endpoint or again a topic in Kafka. The advantage of that encapsulation is that the Data Product can be developed without interfering other data pipelines from other Data Products, I can start with a simple pass-through and add further transformations steps as soon as I need them. And it can be easily extended on new output ports (e.g. starting with a S3 endpoint, later a REST endpoint) Sounds quite similar to the hexagonal architecture? Yes, and reflects the movement to more Microservices in the non-analytical world. And on the Data & Analytics domain we see similar patterns, Data Mesh opens the door towards Domain Driven Development, Serverless, Data Products (within Data Mesh), Event-Driven are pushing towards Microservices / more granular processes.
So, back to the initial question: Is Data Mesh not so new? Well, from my view it is and it is not.
- It is not: Data Mesh uses approaches and concepts from the Software Engineering domain like domain driven design, hexagonal architecture, Microservices etc.
- It is: these concepts were not the standard way of working in Data & Analytics Space in the last years and therefore a quite new approach. But it is good and helps to bring the data-driven thinking and data-diven practise forward.